dipl-Transkription
Die grundlegende, diplomatische Ebene (dipl) beinhaltet die Transkription von Faksimilés und stellt den ersten Schritt für die korpuslinguistische Aufbereitung dar.
Diese Ebene soll sich grafisch hinsichtlich Orthografie, Getrennt- und Zusammenschreibung und Sonderzeichen möglichst nah am zugrunde liegenden Faksimile orientieren. Grundsätzlich wird so auch entgegen modernen Orthografieregeln segmentiert oder transkribiert. Sie wird entweder durch OCR (Optical Character Recognition) oder manuell erstellt und korrigiert.
In diesem Abschnitt finden sich folgende Informationen:
OCR
Als Grundlage für die dipl-Ebene dienen Faksimiles der Primärwerke. Um aus diesen maschinenlesbaren Text zu erhalten, wird OCR4all genutzt. Der Workflow besteht aus folgenden Schritten:
- Preprocessing
- Noise removal (optional)
- Segmentation mit LAREX
- Line Segmentation
- Recognition
- Ground Truth Production mit LAREX
- Training (optional)
Weitere Details und Dokumentation: https://www.ocr4all.org/guide/user-guide/introduction
Der OCR-Output wird mit dem TreeTagger tokenisiert und die Tokenisierung manuell nachbearbeitet korrigiert.
Fußnoten und Marginalien müssen gemäß den Transkriptionsrichtlinien unter Umständen neu platziert werden (siehe Annotationsebene note).
Manuelle Transkription
Die manuelle Transkription wurde im txt-Format erstellt und in das xlsx-Format importiert. In der UTF-8-kodierten txt-Datei dienen die Leerzeichen als Tokentrenner.
Transkriptionsrichtlinien
Transkribieren
Allgemeine Richtlinien und Hinweise
- Nicht mehr lesbare Zeichen oder Zeichenketten werden mit einem Unterstrich (
_) markiert, unabhängig davon, wieviele Zeichen (in etwa) nicht mehr interpretiert werden können.
- Handschriftliche Versalien, die offensichtlich zum Text gehören (KEINE Anmerkungen oder Kommentare von Lesern), werden mit annotiert.
| Faksimilé | dipl |
|---|---|
 | ABſinthium |
Lautzeichen
Die Zeichen für “I” und “J” sind in Fraktur-Texten grafisch häufig nicht voneinander unterscheidbar. Konvention in RIDGES ist daher, das Zeichen in der dipl als J darzustellen und erst in der norm-Ebene das Zeichen individuell nach moderner Orthografie zu interpretieren.
| Faksimilé | dipl |
|---|---|
Jſt |
Das ſ wird beibehalten.
| Faksimilé | dipl |
|---|---|
Leſer |
- “Ʒ” (bzw. “ʒ”) wird nicht von “Z” (bzw. “z”) unterschieden. Beide Varianten werden als
Z(bzw.z) transkribiert.
- Unabhängig vom Erscheinungsbild der Zeichen “x”, “y” und “z” (z.B. “y” mit Trema, verzierte Varianten) werden die Zeichen “x”, “y” bzw. “z” als
x,y, bzw.ztranskribiert. Für Beispiele siehe Abschnitt Zeichen.
Diakritika
Alle Akzente werden beibehalten.
| Faksimilé | dipl |
|---|---|
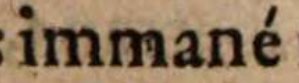 | immané |
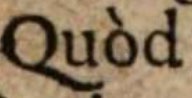 | Quòd |
 | vitâ |
Superskribiertes “e” und “o” werden beibehalten.
| Faksimilé | dipl |
|---|---|
 | genaͤdiger |
zů |
Unabhängig vom Erscheinungsbild des Punktes beim “i” und “ü” (z.B. schräg) wird in der Transkription nicht unterschieden.
| Faksimilé | dipl |
|---|---|
die | |
 | fünff |
Alle horizonalen Striche über einem Zeichen werden als Tilde ( ̃ ) transkribiert.
Eine Tilde repräsentiert in der Regel einen Nasalstrich:
| Faksimilé | dipl |
|---|---|
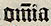 | om̃ia |
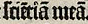 | sciẽtiã meã |
eı̃ | |
 | ſamẽ |
 | eynẽ |
 | nẽlich |
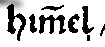 | him̃el |
iñ |
Das Dicit-Zeichen (Abkürzung für “er”) wird in der dipl-Ebene auf zwei unterschiedliche Arten repräsentiert:
| Faksimilé | dipl | Beschreibung |
|---|---|---|
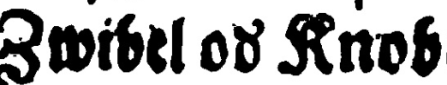 | oð | Dicit-Repräsentation mit ð |
 | v̉tzerẽ | Dicit-Repräsentation mit ̉ |
| Faksimilé | dipl |
|---|---|
| v̉tzerẽ |
- Folgendes Zeichen wird mit
ꝰrepräsentiert:
| Faksimilé | dipl |
|---|---|
deꝰ |
Satzzeichen
Das Zeichen für morphologische Worttrennung oder Zeilenumbruch kann im Faksimilé ⸗ mit dargestellt sein und wird beibehalten.
| Faksimilé | dipl |
|---|---|
Dañ⸗reiſz |
Halbgeviertstriche (en dash, “–”) und Geviertstriche (em dash, “—”) werden als einfache Bindestriche (-) transkribiert.
Das “modifizierende Pluszeichen” (˖) wird beibehalten.
| Faksimilé | dipl |
|---|---|
˖ |
Das Absatzzeichen (¶) wird in der dipl-Ebene beibehalten.
| Faksimilé | dipl |
|---|---|
¶ |
Anführungszeichen werden übernommen.
Ligaturen
- Vokalische Ligaturen werden beibehalten (
æundÆ;Œundœ).
| Faksimilé | dipl |
|---|---|
hæc |
- Die ct-Ligatur wird nicht beibehalten.
| Faksimilé | dipl |
|---|---|
Lactucis |
- Die Ligatur aus “v̈” und “v” wird aufgelöst:
v̈v
| Faksimilé | dipl |
|---|---|
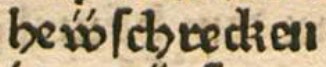 | hev̈vſchrecken |
- “ß” wird in Frakturtexten mit dem langen “ſ” und “z” als
ſztranskribiert, da hier eine Unterscheidung zwischen der Ligatur und den beiden Einzelzeichen häufig schwierig ist. In Antiqua-Texten wird die Ligatur beibehalten.
| Faksimilé | dipl |
|---|---|
 | Uberfluſz |
- Griechische Ligaturen werden nicht abgebildet, sondern bereits in der dipl aufgelöst.
Als Hilfe: https://de.wikipedia.org/wiki/Griechisches_Alphabet#/media/File:Greek_alphabet_ligatures.jpg
{kind=link}
| Faksimilé | dipl |
|---|---|
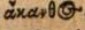 [Ligatur aus o und ς] | ἄκανθος |
- Die lateinische Abkürzung für “etc.” wird als
&undc.transkribiert (2 Token).
| Faksimilé | dipl |
|---|---|
& c. [2 Token] |
- Das kaufmännische Und (
&) wird beibehalten.
| Faksimilé | dipl |
|---|---|
& |
Andere Schriftsysteme
- Andere Schriftsysteme (z.B. Griechisch) werden beibehalten.
UTF-8-Kodierungen für das Griechische siehe hier:
http://www.unicode.org/charts/PDF/U0370.pdf
sowie
http://www.unicode.org/charts/PDF/U0370.pdf
| Faksimilé | dipl |
|---|---|
| ἄκανθος |
Typographische Besonderheiten
- Oft werden die ersten Zeichen bzw. ersten Wörter (im Bsp. Von Weg⸗) einer neuen Seite bei einem Seitenumbruch in der vorhergehenden Seite in einem eigenen Absatz/in einer eigenen Zeile doppelt realisert (sog. Kustoden). Diese Zeichen bzw. das Wort wird nicht mit in das Transkript aufgenommen.
Segmentieren
- Auch entgegen moderner Orthografieregeln wird analog zur Textgrundlage segmentiert.
| Faksimilé | dipl |
|---|---|
 | Spannen⸗lang |
zuſetzen |
Wort
- Zusammengeschriebene klitisierte Elemente werden zusammengeschrieben transkribiert.
| Faksimilé | dipl |
|---|---|
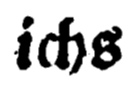 | ichs |
- Im Falle einer Worttrennung aufgrund von Zeilenumbrüchen, die keine overte, grafische Markierung wie “⸗” oder “-” beinhalten, werden formal die getrennten Elemente als jeweils ein Token in der dipl-Ebene repräsentiert.
| Faksimilé | dipl |
|---|---|
ge nent [2 Token] |
- Komposita, egal welcher Komplexität oder Bildungsweise, mit Gleichheitszeichen werden als ein Token realisiert.
| Faksimilé | dipl |
|---|---|
Artzney⸗Kunſt [1 Token] |
Zeilenumbrüche
- Von Zeilenumbrüchen betroffene Elemente werden analog zur Primärquelle getrennt tokenisiert.
| Faksimilé | dipl |
|---|---|
allge⸗ meinen [2 Token] |
- Von Zeilenumbrüchen betroffene Komposita werden analog zur Primärquelle getrennt tokenisiert, dabei bleibt die Kennzeichnung der morphologischen Worttrennung unberührt.
| Faksimilé | dipl |
|---|---|
Stab⸗ wurtz⸗Oel [2 Token] |
Abkürzungen
- Abkürzungen werden analog zur Textgrundlage tokenisiert. Das heißt, auch Setzfehler oder Spatien, die nicht modernen Orthografieregeln entsprechen, werden realisiert.
| Faksimilé | dipl |
|---|---|
u. ſ. w. [3 Token] | |
u d.g. [2 Token] |
Zahlen
- Punktsetzungen bei Ordinalzahlen werden mit der Ziffer als ein Token realisiert.
| Faksimilé | dipl |
|---|---|
I. |
- Die Faksimilia weisen oft Kardinalzahlen mit Interpunktion auf. Diese Punktsetzungen werden mit der jeweiligen Ziffer als Token realisiert. Ausnahmen bilden Zahlen, die mit einem satzbeenden Punkt auftreten. Hier wird wie gewohnt die Satzinterpunktion getrennt von der Kardinalzahl tokenisiert.
| Faksimilé | dipl |
|---|---|
 | I. Loth [2 Token] |
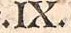 | .IX. [1 Token] |
- Zeichenketten wie “5 %”, “5-12”, “800’” werden auf der dipl und clean als ein Token und in der norm als mehrere Token betrachtet, wenn sie im Scan keine Spatien erkennbar sind. Sind Spatien erkennbar, werden sie auch als verschiedene Token realisiert.
- Bruchangaben werden mit
/beibehalten. Dabei wird getrennt segmentiert, um gemischte Brüche transparent zu halten.
| Faksimilé | dipl |
|---|---|
11/2 [Das sind 2 Token] |
Satzzeichen
- Satzinterpunktionszeichen wie Kommata, Punkte, Virgeln oder Semikola werden als jeweils eigenständige Token realisiert.
| Faksimilé | dipl |
|---|---|
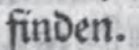 | finden . [2 Token] |
- Höher dargestellte Punkte werden als normale Punkte repräsentiert, da nicht immer zweifelsfrei festgestellt werden kann, ob die Darstellung beabsichtigt ist oder nicht.
| Faksimilé | dipl |
|---|---|
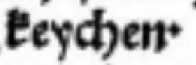 | keychen . [2 Token] |
- Manchmal handelt es sich nicht um Zeichen, sondern Tintenabdrücke im Faksimilé. Diese werden nicht repräsentiert.
| Faksimilé | dipl |
|---|---|
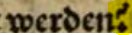 | werden . [2 Token] |
Fußnoten
- Fußnotenreferenzierungen werden in dipl- und clean-Ebene als mehrere Token und in der norm-Ebene als ein Token realisiert.
| Faksimilé | dipl |
|---|---|
( * ) [3 Token] | |
* * ) [3 Token] |
Graphematik
- Text hinter (geschweiften) Klammern, wird nach dem umklammerten Textabschnitt eingefügt. 1
| Faksimilé | dipl |
|---|---|
 | Wermuth Wermuth , gemeiner Wermuth , groſzer ſ. Wer⸗ muthbeifuſz . |
Textrepräsentation
- Der Text der Marginalie wird immer am Anfang des jeweiligen Absatzes, in dem/neben dem sie realisiert ist aufgenommen, unabhängig davon, ob so mehrere Marginalien hintereinander oder/und auf der nachfolgenden Seite realisiert werden müssen. Sie unterbrechen somit den Fließtext.
- Der Text der Fußnote wird immer am Ende des Absatzes, in dem sie eingepflegt ist aufgenommen, unabhängig davon, ob sich so die Fußnoten sammeln oder erst auf der nachfolgenden Seite realisiert werden müssten. Sie unterbrechen somit den Fließtext. Geht eine Fußnote über mehrere Seiten, wird sie zusammenhängend transkribiert.
Zeichen
| Faksimilé | dipl | Beschreibung |
|---|---|---|
x | Dieses Zeichen ist ein x. | |
y | Dieses Zeichen ist ein y. | |
z | Dieses Zeichen ist ein z. | |
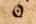 | ⊙ | Das Sonnensymbol wird beibehalten. |
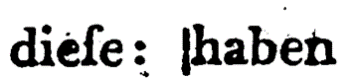 | dieſe | | Senkrechtstriche werden mit | beibehalten. |
 | $ | Dieses Symbol wird als $ transkribiert. Es bedeutet wahrscheinlich “Zwitter” bzw. “zwitterig” (botanischer Fachbegriff). |
⁊ | Dieses Zeichen wird als ⁊ transkribiert. Es handelt sich hierbei um das Tironische “et”. | |
v̈v | Dies ist eine Ligatur aus “v̈” und “v”. Sie wird in der dipl-Ebene aufgelöst. Siehe Abschnitt Ligaturen. | |
& c. [2 Token] | Dies ist eine lateinische Abkürzung für “etc.” Sie wird als & und c. transkribiert (siehe Abschnitt Ligaturen). |
Für Beispiele und Einzelfallentscheidungen siehe Übersicht.
Automatische Tokensierung
Die mit OCR erstellten Transkriptionen müssen noch tokenisiert werden, bevor sie nach Excel konvertiert werden müssen.
Dafür nutzen wir das Bash-Script tokenize-ocr4all.sh im scripts Ordner und dem Tokenizer vom TreeTagger.
Das Script wir in der Kommandozeile (unter Linux oder MacOS) aufgerufen und benötigt den Installationsordner vom TreeTagger und dem Ordner mit den Textdateien aus OCR4all (txt/RIDGES_Herbology/) als Argument.
./scripts/tokenize-ocr4all.sh TREETAGGER_ORDNER txt/RIDGES_Herbology/
Das Script ersetzt nach dem Ausführen alle Textdateien mit der Endung .txt mit Dateien im TreeTagger-Format und der Endung (.tt) im selben Ordner.
Die Zeilen- und Seiteninformationen aus den Textdateien bleiben als lb bzw. pb Annotation erhalten.
Die Konvertierung der Dateien in txt/RIDGES_Herbology/ in das Excel-Format (im Ordner Excel/RIDGES_Herbology) erfolgt dann über eine Annatto-Workflowdatei.
annatto run tt2excel.toml
Dieser Schritt erstellt auch die automatische clean-Ebene.