clean-Normalisierung
Die clean-Ebene enthält erste vollautomatisch erstellte Normalisierungen hinsichtlich Sonderzeichen und graphischer Strukturierungen. Sie wird automatisch beim Konvertieren von TreeTagger nach Excel erstellt.
Alternativ kann die clean-Ebene für die bestehenden Excel-Dateien neu erstellt werden, indem man die Annatto-Workflowdatei reclean.toml ausführt
annatto run reclean.toml
Über diesen Konvertierungs-Schritt werden u.a. Ligaturen, die nach moderner Rechtschreibung nicht mehr verwendet werden, normalisiert. Graphische Markierungen der einzelnen Texte wie Zeilenumbrüche werden aufgelöst und Sonderzeichen einiger Fonts wie Fraktur auf die heutigen Schriftsätze übertragen. Für die Token, die Vokale mit Tilden enthalten, werden alle möglichen Formen dieser Token in der clean angegeben. Die verschiedenen Formen werden durch | getrennt (zum Beispiel: auſzwēdig wird zu auszwemdig|auszwendig).
In der clean-Ebene werden außerdem Wörter, die durch einen Zeilenumbruch getrennt und mit einem Bindeelement versehen sind, zusammengezogen. Beginnt das zweite Wort mit einem Großbuchstaben, wird dieser in der clean-Ebene in Kleinschreibung realisiert. Ist der komplette zweite Bestandteil in Großbuchstaben geschrieben, bleibt dies so bestehen (Gelb-Sucht wird zu Gelbsucht; MON- <lb> TANUM wird zu MONTANUM).
Trunkierte Elemente, die am Zeilenende stehen, werden bisher nicht als solche erkannt und daher automatisch mit dem ersten Element der folgenden Zeile zusammengezogen (Speiſz⸗und Nahrungs⸗Saffts wird zu Speiszund (sic!) Nahrungssaffts).
Für eine komplette Auflistung aller Ersetzungen, die für die Erstellung der clean-Ebene gemacht wurden, siehe die Readme zum Skript.
Richtlinien für die clean-Normalisierung
Normalisieren
Allgemeine Richtlinien und Hinweise
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
_ | unknown | Bei nicht lesbaren Zeichen oder Zeichenketten ist durch die fehlende Transkription ist eine Normalisierung nicht mehr möglich. Dies wird mit dem Platzhalter-Tag unknown angezeigt. | |
 | ABſinthium | ABsinthium | Handschriftliche Versalien, die offensichtlich zum Text gehören (KEINE Anmerkungen oder Kommentare von Lesern), werden in der dipl mit annotiert und in der clean übernommen. |
Lautzeichen
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
Jſt | Jst | Die Zeichen für ‘I’ und ‘J’ sind in Fraktur-Texten grafisch häufig nicht voneinander unterscheidbar. In der clean-Ebene wird J beibehalten. | |
Leſer | Leser | Das lange “ſ” wird durch ein reguläres s ersetzt. |
Diakritika
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
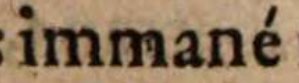 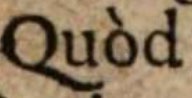  | immané Quòd vitâ | immané Quòd vitâ | Alle Akzente werden beibehalten. |
zů | zu | Superskribiertes “o” wird in der clean-Ebene nicht mehr realisiert und durch den zugrundeliegenden Vokal ersetzt. | |
 | genaͤdiger | genädiger | Vokalgrapheme mit superskribiertem “e” werden in der clean-Ebene in Umlaute des modernen Deutschen umgewandelt. |
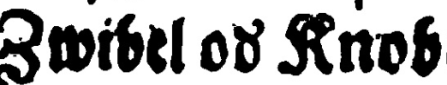  | oð v̉tzerẽ | oder vertzeren | Das Dicit-Zeichen (ð oder ̉ ) wird in der clean automatisch mit er ersetzt |
deꝰ | deus | Das ꝰ-Zeichen wird in der clean-Ebene durch us ersetzt. |
Tilden werden entsprechend ihrer Funktion als Nasalstriche aufgelöst.1 Achtung: In der clean-Ebene wird der Strich automatisch als Nasalstrich interpretiert und nicht immer korrekt zwischen “m” und “n” unterschieden:2
| Faksimilé | dipl | clean |
|---|---|---|
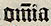 | om̃ia | omnia |
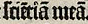 | sciẽtiã meã | scientiam meam |
eı̃ | ein | |
 | ſamẽ | samen |
 | eynẽ | eynem |
 | nẽlich | nemlich |
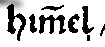 | him̃el | himmel |
iñ | inn |
Satzzeichen
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
Dañ⸗reiſz | Dann-reisz | Die morphologische Trennung durch “⸗” bleibt erhalten, wird jedoch mit einem regulären Bindestrich (-) ersetzt. Komposita, die in der dipl-Ebene mit einem ⸗ realisiert werden, behalten dieses Zeichen bei, um die allgemeine Suche nach Komposita in dieser Ebene zu ermöglichen. Für Erläuterungen zur rein grafischen Trennung, wie Zeilenumbrüchen, siehe Abschnitt Segmentieren. | |
˖ | : | In der clean wird das “modifizierende Pluszeichen” (˖) zu : normalisiert. | |
¶ | ¶ | Das Absatzzeichen (¶) wird in dipl-, clean- und norm-Ebene übernommen. |
Ligaturen
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
hæc | haec | Die Ligaturen æ und Æ werden aufgelöst. Das gleiche gilt ebenfalls für Œ und œ. | |
 | Uberfluſz | Uberflusz | Die “ß”-, bzw. “ſz”-Ligatur wird analog zu dipl aufgelöst: sz. |
& c. | & c. | Folgendes beteutet “etc.”. Es wird als & und c. transkribiert (2 Token). | |
& | & | Das kaufmännische Und (&) wird übernommen. |
Andere Schriftsysteme
- Sprachliches Material mit anderen Schriftsystemen (z.B. Griechisch) wird in clean und norm nicht geändert.
http://www.unicode.org/charts/PDF/U0370.pdf
sowie
http://www.unicode.org/charts/PDF/U0370.pdf
| Faksimilé | dipl | clean |
|---|---|---|
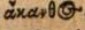 | ἄκανθος | ἄκανθος |
Segmentieren
| dipl | clean |
|---|---|
Spannen⸗lang | Spannen-lang |
zuſetzen | zusetzen |
Wort
| dipl | clean | Beschreibung |
|---|---|---|
ichs | ichs | Klitika werden als ein Token realisiert. |
ge nent [2 Token] | ge nent [2 Token] | Die Worttrennung ohne grafische Markierung ist nicht in jedem Fall transparent. Grafische Normalisierungen werden nicht vorgenommen. |
Artzney⸗Kunſt [1 Token] | Artzney-Kunst [1 Token] | Die morphologische Trennung von Komposita durch “⸗” bleibt erhalten, wird jedoch mit einem regulären - ersetzt. |
Zeilenumbrüche
| Faksimilé | dipl | clean | Beschreibung |
|---|---|---|---|
allge⸗ meinen [2 Token] | allgemeinen [1 Token] | Wörter, die von Zeilenumbrüchen betroffen sind, werden in der clean-Ebene ohne den (Doppel-) Bindestrich, der diesen anzeigt, sowie in einer Spanne zusammengefasst realisiert. Die grafische Worttrennung wird somit aufgehoben. | |
Stab⸗ wurtz⸗Oel [2 Token] | Stabwurtz-Oel [1 Token] | Wenn ein Kompositum, das durch Gleichheitszeichen grundsätzlich getrennt wird, von einem Zeilenumbruch betroffen ist, so wird dieses Gleichheitszeichen in der clean-Ebene entfernt, das andere Gleichheitszeichen für die morphologische Trennung wird analog zum Abschnitt Wort mit einem Minus ersetzt. Das Kompositum wird in einer Spanne zusammengefasst wiedergegeben. |
Abkürzungen
Abkürzungen werden in der clean-Ebene analog zur dipl-Ebene tokenisiert.
| dipl | clean |
|---|---|
u. ſ. w. [3 Token] | u. s. w. [3 Token] |
u d.g. [2 Token] | u d.g. [2 Token] |
Zahlen
Bei Zahlen werden in der clean-Ebene alle Konventionen der dipl-Ebene übernommen.
Satzzeichen
Für Satzzeichen werden in der clean-Ebene alle für die dipl-Ebene beschriebenen Konventionen übernommen.
Fußnoten
Für Fußnoten werden in der clean-Ebene alle für die dipl-Ebene beschriebenen Konventionen übernommen.
- Der Text der Marginalie wird immer am Anfang des jeweiligen Absatzes, in dem/neben dem sie realisiert ist, unabhängig davon, ob so mehrere Marginalien hintereinander oder/und auf der nachfolgenden Seite realisiert werden müssen, in die dipl-Ebene/Transkription aufgenommen.
- Der Text der Fußnote wird immer am Ende des Absatzes, in dem sie eingepflegt ist, unabhängig davon, ob sich so die Fußnoten sammeln oder erst auf der nachfolgenden Seite realisiert werden müssten, in die dipl-Ebene/Transkription aufgenommen. Geht eine Fußnote über mehrere Seiten, wird sie zusammenhängend transkribiert.
- Nicht mehr lesbare Zeichen oder Zeichenketten werden mit einem Unterstrich (
_) markiert, unabhängig davon, wieviele Zeichen (in etwa) nicht mehr interpretiert werden können. Zusätzlich wird in einem späteren Schritt die Stelle auf der Annotationsebene “unclear” gekennzeichnet. - Halbgeviertstriche (en dash, “–”) und Geviertstriche (em dash, “—”) werden als einfache Bindestriche (
-) transkribiert, da in älteren Drucken eine Unterscheidung oft schwierig ist.