Transkription und Normalisierung: Übersicht
Nachfolgend werden die Richtlinien zur Transkription und Normalisierung im Einzelnen gegenübergestellt. Allgemein für jede Segmentierungsebene sowie Annotationsebene gilt, dass keine Leerzeilen oder Leerzeichen enthalten sein dürfen. Dazu wird für jeden Fall ein Beispiel gegeben, die konkrete Regel beschrieben und die weiteren Normalisierungsschritte gegenübergestellt (dipl – clean – norm). Die Richtlinien sind nach Schwerpunkten gruppiert:
(1) Zeichensetzung/Sonderzeichen
(2) Segmentierung/Tokenisierung
(3) Interpunktion.
Sonderzeichen wie zum Beispiel das “ſ” werden mit Hilfe von Unicodes in der dipl-Ebene realisiert. Eine Liste der zu verwendenden Unicodes ist angefügt.
| Nr. | dipl-Ebene | clean-Ebene | norm-Ebene |
|---|---|---|---|
| Transkript des Faksimiles. | Wird automatisch durch ein Python-Skript (clean-skript.py) erstellt. Dieses ersetzt alle heute unüblichen Sonderzeichen durch heute verwendete Entsprechungen. | Erfolgt manuell im .xlsx Format nach der modernen neuen Rechtschreibung. Tipp: Kopieren Sie sich die clean-Ebene und verändern Sie dann die entsprechenden Stellen! |
|
| 1.0 | Nicht mehr lesbare Zeichen oder Zeichenketten werden mit einem Unterstrich markiert, unabhängig davon, wieviele Zeichen (in etwa) nicht mehr interpretiert werden können. | Durch die fehlende Transkription ist eine Normalisierung nicht mehr möglich. Dies wird mit dem Platzhalter-Tag "unknown" angezeigt. | Durch die fehlende Transkription ist eine Normalisierung nicht mehr möglich. Dies wird mit dem Platzhalter-Tag "unknown" angezeigt. |
| dipl | clean | norm | |
_ |
unknown |
unknown |
|
Handschriftliche Versalien, die offensichtlich zum Text gehören (KEINE Anmerkungen oder Kommentare von Lesern), werden mit annotiert.
| |||
| dipl | clean | norm | |
ABſinthium |
ABsinthium |
ABsinthium |
|
| 1.1 | Die Zeichen für 'I' und 'J' sind in Fraktur-Texten grafisch in der Regel nicht voneinander unterscheidbar. Konvention in RIDGES ist daher, das Zeichen in der dipl als J darzustellen und erst in der norm-Ebene das Zeichen individuell nach moderner Orthografie zu interpretieren. |
Wie in der dipl-Ebene. | Anpassung an moderne Orthografie. |
| dipl | clean | norm | |
Jſt |
Jst |
Ist |
|
| 1.2 | Das ſ wird übernommen. |
Das lange "ſ" wird durch ein reguläres s ersetzt. |
|
| dipl | clean | norm | |
Leſer |
Leser |
Leser |
|
 Dies ist ein x |
|||
| dipl | clean | norm | |
x |
x |
x |
|
Das Zeichen Ʒ (bzw. ʒ) wird in der dipl-Ebene nicht von Z (bzw. z) unterschieden. Beide Varianten werden als Z (bzw. z) transkribiert. |
Wie in der dipl-Ebene. | ||
| dipl | clean | norm | |
 Dies ist ein z |
z |
z |
|
In manchen Drucken sieht das Zeichen y etwas anders aus; es wird aber als "normales" y transkribiert. |
|||
| dipl | clean | norm | |
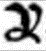 Dies ist ein y |
y |
y |
|
| 1.3 | Alle Akzente werden übernommen. | Alle Akzente werden übernommen. | Alle Akzente werden übernommen. |
| dipl | clean | norm | |
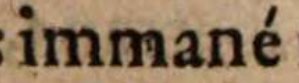 immané |
immané |
immané |
|
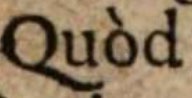 Quòd |
Quòd |
Quòd |
|
 vitâ |
vitâ |
vitâ |
|
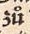 Dieses Zeichen wirdübernommen. |
Dieses diakritische Zeichen wird in der clean-Ebene nicht mehr realisiert und durch den zugrundeliegenden Vokal ersetzt. | ||
| dipl | clean | norm | |
zů |
zu |
zu |
|
 Umlaute mit superskribiertem "e" werden übernommen. |
Umlaute mit superskribiertem "e" werden wie moderne Umlaute des Deutschen realisiert. | ||
| dipl | clean | norm | |
genaͤdiger |
genädiger |
gnädiger |
|
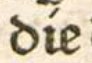 'í' mit schrägem Strich wird nicht vom 'i' mit Punkt unterschieden. Beide Varianten werden als i transkribiert. |
|||
| dipl | clean | norm | |
die |
die |
die |
|
 Das "ű" mit schrägen Strichen wird nicht nicht vom ü mit Punkten unterschieden. Beide Varianten werden als ü transkribiert. |
|||
| dipl | clean | norm | |
fünff |
fünff |
fünf |
|
Alle horizonalen Striche über einem Zeichen werden als Tilde ( ̃̃ ) interpretiert.Eine Tilde kann stehen für: ausgelassene Nasale, sog. Nasalstrich |
Tilden werden entsprechend ihrer Funktion umgesetzt. Die kann u. a. aus Reichmann & Wegera (1993) entnommen werden.1 Achtung: In der clean-Ebene wird der Strich automatisch als Nasalstrich interpretiert. Gegebenenfalls in der norm ausgleichen. |
Gegebenenfalls in der clean-Ebene eingefügte Nasale anders umsetzen. | |
| dipl | clean | norm | |
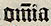 om̃ia |
omnia |
omnia |
|
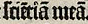 sciẽtiã meã |
scientiam meam |
scientiam meam |
|
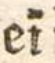 eı̃ |
ein |
ein |
|
 samẽ |
samen |
Samen |
|
 einẽ |
eynem |
einem |
|
 nẽlich |
nemlich |
nämlich |
Verdopplung eines Buchstabens |
| dipl | clean | norm | |
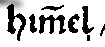 him̃el |
himmel |
Himmel |
|
 iñ |
inn |
in |
|
 Das Dicit-Zeichen (Abkürzung für "der") wird in der dipl-Ebene mit ð übernommen |
Es wird in der clean automatisch mit "der" ersetzt | In der norm auch. | |
| dipl | clean | norm | |
oð |
oder |
oder |
|
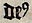 Dieses Zeichen wird mit ꝰ repräsentiert. |
Ersetzung durch us |
Ersetzung durch us |
|
| dipl | clean | norm | |
deꝰ |
deus |
deus |
 |
Ersetzung durch er |
Ersetzung durch er |
| dipl | clean | norm | |
v̉tzerẽ |
vertzeren |
verzehren |
|
| 1.4 |  Das Zeichen für morphologische Worttrennung (oder Zeilenumbruch) wird mit ⸗ übernommen. |
Die morphologische Trennung durch "⸗" bleibt erhalten, wird jedoch mit einem regulären - ersetzt. Komposita, die in der dipl-Ebene mit einem ⸗ realisiert werden, behalten dieses Zeichen bei, um die allgemeine Suche nach Komposita in dieser Ebene zu ermöglichen. Für Erläuterungen zur rein grafischen Trennung, wie Zeilenumbrüchen, siehe Nummer 2.1. |
Gleichheitszeichen, die Kompositabildung anzeigen, werden durch Minuszeichen (-) ersetzt oder das Kompositum wird analog zur modernen Orthografie zusammengeschrieben (Grundlage hierfür ist der aktuelle Stand des Dudens). |
| dipl | clean | norm | |
Dañ⸗reiſz |
Dann-reisz |
Tannenreis |
Halbgeviertstriche (en dash, "–") und Geviertstriche (em dash, "—") werden als einfache Bindestriche (-) transkribiert. |
| dipl | clean | norm | |
- |
- |
- |
|
Das "modifizierende Pluszeichen" (˖) wird übernommen. |
In der clean wird das Zeichen zu : normalisiert. |
In der norm wird das Zeichen zu : normalisiert. |
|
| dipl | clean | norm | |
˖ |
: |
: |
|
Das Absatzzeichen (¶) wird in dipl-, clean- und norm-Ebene übernommen. |
|||
| dipl | clean | norm | |
¶ |
¶ |
¶ |
|
| 1.5 | Bruchangaben werden mit / übernommen. Dabei wird getrennt segmentiert, um gemischte Brüche transparent zu halten. |
Bruchangaben werden mit / übernommen. Dabei wird getrennt segmentiert, um gemischte Brüche transparent zu halten. |
Bruchangaben werden mit / übernommen. Dabei wird getrennt segmentiert, um gemischte Brüche transparent zu halten. |
| dipl | clean | norm | |
1 |
1 |
1 |
|
1/2 |
1/2 |
1/2 |
|
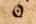 Dieses Symbol wird übernommen. |
Dieses Symbol wird übernommen. | Dieses Symbol wird übernommen. | |
| dipl | clean | norm | |
⊙ |
⊙ |
⊙ |
|
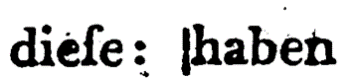 Senkrechtstriche werden mit | übernommen. |
Senkrechtstriche werden übernommen. | Senkrechtstriche werden übernommen. | |
| dipl | clean | norm | |
dieſe |
diese |
diese |
|
| |
| |
| |
|
 Dieses Symbol wird als $ transkribiert. Es bedeutet wahrscheinlich "Zwitter" bzw. "zwitterig". |
Die als Platzhalter dienenden Dollarzeichen werden übernommen. | Dollarzeichen werden übernommen. In der Ebene "comment" kann ergänzt werden, dass das Zeichen vermutlich "Zwitter" oder "zwitterig" bedeutet. | |
| dipl | clean | norm | |
$ |
$ |
$ |
|
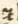 Dieses Zeichen wird als ⁊ transkribiert. Es handelt sich hierbei um das Tironische "et". |
|||
| dipl | clean | norm | |
⁊ |
et |
et |
|
| 1.6 | Die Ligaturen æ und Æ werden übernommen. Das gleiche gilt ebenfalls für Œ und œ |
Die Ligatur wird aufgelöst. | |
| dipl | clean | norm | |
hæc |
haec |
haec |
|
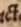 Die ct-Ligatur wird nicht übernommen. |
Die ct-Ligatur wird nicht übernommen. | Die ct-Ligatur wird nicht übernommen. | |
| dipl | clean | norm | |
Lactucis |
Lactucis |
Lactucis |
|
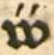 Dies ist eine Ligatur aus v̈ und v. Die Ligatur wird aufgelöst: v̈v |
v̈v |
||
| dipl | clean | norm | 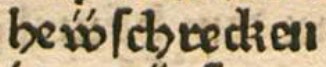 hev̈vſchrecken |
hev̈vschrecken |
Heuschrecken |
Die ſz-Ligatur wird mit dem langen "ſ" und "z" übernommen: ſz |
Die Ligatur wird analog zu dipl aufgelöst: sz |
Nach modernen Orthografieregeln wird für "sz" das ß verwendet. |
|
| dipl | clean | norm | |
 Uberfluſz |
Uberflusz |
Überfluss |
|
Griechische Ligaturen werden nicht abgebildet, sondern bereits in der dipl aufgelöst: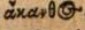 Ligatur aus o und ς Als Hilfe: https://de.wikipedia.org/wiki/Griechisches_Alphabet#/media/File:Greek_alphabet_ligatures.jpg |
|||
| dipl | clean | norm | |
ἄκανθος |
ἄκανθος |
ἄκανθος |
|
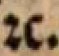 Dies beteutet "etc." |
|||
| dipl | clean | norm | |
& |
& |
etc. |
|
c. |
c. |
||
Das kaufmännische Und (&) wird übernommen. |
Das kaufmännische Und (&) wird übernommen. |
Das kaufmännische Und (&) wird übernommen. |
|
| dipl | clean | norm | |
& |
& |
& |
|
| 1.7 | Sprachliches Material mit anderen Schriftsystemen (z.B. Griechisch) wird in clean und norm nicht geändert. http://www.unicode.org/charts/PDF/U0370.pdf sowie http://www.unicode.org/charts/PDF/U0370.pdf |
||
| dipl | clean | norm | |
ἄκανθος |
ἄκανθος |
ἄκανθος |
|
| 1.8 | Oft werden die ersten Zeichen bzw. ersten Wörter (im Bsp. Von Weg⸗) einer neuen Seite bei einem Seitenumbruch in der vorhergehenden Seite in einem eigenen Absatz/in einer eigenen Zeile doppelt realisert (sog. Kustoden). Diese Zeichen bzw. das Wort wird nicht mit in das Transkript aufgenommen. | ||
| 2 |  Auch entgegen moderner Orthografieregeln wird analog zur Textgrundlage tokenisiert. |
Wortbildung und Großschreibung, die nicht der modernen Orthografieregeln entsprechen, werden angeglichen. | |
| dipl | clean | norm | |
Spannen⸗lang |
Spannen-lang |
spannenlang |
|
| 2.1 | Klitisierte Elemente können zusammengeschrieben (z.B. ichs, bedarfs, aufs) oder apostrophiert dargesetllt sein (z.B. ich's, bedarf's, auf's). Klitisiert werden schwach betonte Morpheme. Z.B.: Formen des Personalpronomens, unbestimmter oder bestimmter Artikel | Klitika werden als ein Token realisiert. | Klitika werden in dieser Ebene aufgelöst. Dazu wird die Tokenisierung verändert, indem aus einem Token in dipl (oder clean) zwei Token gemacht werden!. |
| dipl | clean | norm | |
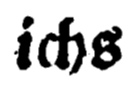 ichs |
ichs |
ich |
|
es |
|||
| Auch entgegen moderner Orthografieregeln wird analog zur Textgrundlage tokenisiert. | Getrennt- und Zusammenschreibung wird nach modernen Orthografieregeln angepasst. Dazu wird die Tokenisierung verändert, indem aus einem Token in der dipl-Ebene (oder clean) zwei Token in der norm-Ebene gemacht werden! | ||
| dipl | clean | norm | |
zuſetzen |
zusetzen |
zu |
|
setzen |
|||
| Im Falle einer Worttrennung aufgrund von Zeilenumbrüchen, die keine overte, grafische Markierung wie "⸗" oder "-" beinhalten, werden formal die getrennten Elemente als jeweils ein Token in der dipl-Ebene betrachtet. Auch entgegen moderner Orthografieregeln wird analog zur Textgrundlage tokenisiert. | Die Worttrennung ohne grafische Markierung ist nicht in jedem Fall transparent. Grafische Normalisierungen werden nicht vorgenommen. | Diese Art der Worttrennung, wenn sie transparent ist, wird nach modernen Orthografieregeln normalisiert und die grafische Trennung aufgehoben. | |
| dipl | clean | norm | |
ge |
ge |
genannt |
|
nent |
nent |
||
| Komposita, egal welcher Komplexität oder Bildungsweise, mit Gleichheitszeichen werden als ein Token realisiert. | Die morphologische Trennung durch "⸗" bleibt erhalten, wird jedoch mit einem regulären "-" ersetzt. | Gleichheitszeichen, die Kompositabildung anzeigen, werden durch Minuszeichen ersetzt oder das Kompositum wird analog zur modernen Orthografie zusammengeschrieben (Grundlage hierfür bildet die aktuelle Ausgabe des Dudens.). | |
| dipl | clean | norm | |
Artzney⸗Kunſt |
Artzney-Kunst |
Arzneikunst |
|
| 2.2 | Von Zeilenumbrüchen betroffene Elemente werden analog zur Primärquelle getrennt tokenisiert. Das Trennungszeichen "⸗" wird übernommen. | Wörter, die von Zeilenumbrüchen betroffen sind, werden in der clean-Ebene ohne den (Doppel-) Bindestrich, der diesen anzeigt, sowie in einer Spanne zusammengefasst realisiert. Die grafische Worttrennung wird somit aufgehoben. | |
| dipl | clean | norm | |
allge⸗ |
allgemeinen |
allgemeinen |
|
meinen |
|||
| Von Zeilenumbrüchen betroffene Komposita werden analog zur Primärquelle getrennt tokenisiert, dabei bleibt die Kennzeichnung der morphologischen Worttrennung unberührt. | Wenn ein Kompositum, das durch Gleichheitszeichen grundsätzlich getrennt wird, von einem Zeilenumbruch betroffen ist, so wird dieses Gleichheitszeichen in der clean-Ebene entfernt, das andere Gleichheitszeichen für die morphologische Trennung wird analog zu Nummer 1.1 mit einem Minus ersetzt. Das Kompositum wird in einer Spanne zusammengefasst wiedergegeben. | Die Gleichheitszeichen, die Kompositabildung anzeigen, werden durch Minuszeichen ersetzt oder das Kompositum wird analog zur modernen Orthografie zusammengeschrieben (Grundlage hierfür bildet die aktuelle Ausgabe des Dudens.). | |
| dipl | clean | norm | |
Stab⸗ |
Stabwurtz-Oel |
Stabwurzöl |
|
wurtz⸗Oel |
|||
| 2.3 | Abkürzungen werden analog zur Textgrundlage tokenisiert. Das heißt, auch Setzfehler oder Spatien, die nicht modernen Orthografieregeln entsprechen, werden realisiert. | Abkürzungen werden nach Dudenrichtlinien umgesetzt. Dies hat zur Folge, dass Abkürzungen unterschiedlich tokenisiert werden können (bspw. Abkürzungen als zwei oder mehr Tokens wie u. a. m. vs. solche, die als ein Token realisiert werden, wie usw.). vgl. dazu beide Beispiele in 2.3. In Fällen, in denen keine Dudenrichtlinie zugeordnet werden kann, wird immer nach einem Punkt segmentiert. | |
| dipl | clean | norm | |
u. |
u. |
usw. |
|
ſ. |
s. |
||
w. |
w. |
||
| Abkürzungen werden analog zur Textgrundlage tokenisiert. Das heißt, auch Setzfehler oder Spatien, die nicht modernen Orthografieregeln entsprechen, werden realisiert. | Abkürzungen werden nach Dudenrichtlinien umgesetzt. Dies hat zur Folge, dass Abkürzungen unterschiedlich tokenisiert werden können (bspw. Abkürzungen als zwei oder mehr Tokens wie u. a. m. vs. solche, die als ein Token realisiert werden, wie usw.). vgl. dazu beide Beispiele in 2.3. In Fällen, in denen keine Dudenrichtlinie zugeordnet werden kann, wird immer nach einem Punkt segmentiert. | ||
| dipl | clean | norm | |
u |
u |
u. |
|
d. |
|||
d.g. |
d.g. |
g. |
|
| 2.4 | Punktsetzungen bei Ordinalzahlen werden mit der Ziffer als ein Token realisiert. | Nach modernen Orthografieregeln werden Ordinalzahlen mit Punkt realisiert. | |
| dipl | clean | norm | |
I. |
I. |
I. |
|
Die Faksimilia weisen oft Kardinalzahlen mit Interpunktion auf. Diese Punktsetzungen werden mit der jeweiligen Ziffer als Token realisiert. Ausnahmen bilden Zahlen, die mit einem satzbeenden Punkt auftreten. Hier wird wie gewohnt die Satzinterpunktion getrennt von der Kardinalzahl tokenisiert. 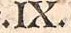 |
Um die Kardinalzahlen von Ordinalzahlen in der norm-Ebene getrennt betrachten zu können, wird die Interpunktion bei Kardinalzahlen weggelassen. | ||
| dipl | clean | norm | |
I. |
I. |
I. |
|
Loth |
Loth |
Loth |
|
.IX. |
.IX. |
IX |
|
| Zeichenketten wie "5 %", "5-12", "800'" werden auf der dipl und clean als ein Token und in der norm als mehrere Token betrachtet, wenn sie im Scan visuell zusammen stehen. Stehen sie visuell auseinander, werden sie auch als verschiedene Tokens realisiert. | Norm: immer als mehrere Token | ||
| 2.5 | 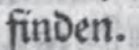 Satzinterpunktion wie Kommata, Punkte, Virgeln oder Semikola werden als jeweils eigenständige Token realisiert. |
||
| dipl | clean | norm | |
finden |
finden |
finden |
|
. |
. |
. |
|
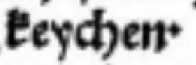 Die Höhe von Punkten wird nicht beachtet. Da wir nicht immer zweifelsfrei feststellen können, wann ein Punkt "hoch" ist und wann "tief", transkribieren wir das alles als normale Punkte. |
|||
| dipl | clean | norm | |
keychen |
keychen |
keuchen |
|
. |
. |
. |
|
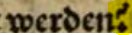 Dieses Zeichen wird als Punkt transkribiert. |
|||
| dipl | clean | norm | |
werden |
werden |
werden |
|
. |
. |
. |
|
| 2.6 | Fußnotenreferenzierungen werden in dipl- und clean-Ebene als mehrere Token und in der norm-Ebene als ein Token realisiert. | Norm: ein Token | |
| dipl | clean | norm | |
( |
( |
(*) |
|
* |
* |
||
) |
) |
||
| dipl | clean | norm | |
* |
* |
**) |
|
* |
* |
||
) |
) |
||
| 3.1 | Formen, die in phonologischer Hinsicht fnhd. oder dialektalen Lautstand aufweisen, werden in der norm den (standard-)nhd. Entsprechungen angepasst. | ||
| dipl | clean | norm | |
Hellenpein |
Hellenpein |
Höllenpein |
|
wänlin |
wänlin |
Wännlein |
|
| Dialektale Formen | |||
| dipl | clean | norm | |
beede |
beede |
beide |
|
| Apokope / Synkope (hier: Synkope) | |||
| dipl | clean | norm | |
hänget |
hänget |
hängt |
|
| 3.2 | Fnhd. Flexionsformen werden durch die nhd. Entsprechungen ersetzt. | ||
| dipl | clean | norm | |
in die Nasen |
in die Nasen |
in die Nase |
|
das kal Haupt |
das kal Haupt |
das kahle Haupt |
|
| Es erfolgt keine Anpassung des Genus | |||
| dipl | clean | norm | |
das Milz |
das Milz |
das Milz |
|
| Vom Nhd. abweichende starke oder schwache Verbalflexion bzw. Rückumlaut wird dem nhd. Stand angepasst | |||
| dipl | clean | norm | |
gennent |
gennent |
genannt |
|
gebauen |
gebauen |
gebaut |
|
| Auseinanderschreibung | |||
| dipl | clean | norm | |
obgenannt |
obgenannt |
oben genannt |
|
hiebevor |
hiebevor |
hier bevor |
|
| 3.3 | Die aus der niederfränkischen Schreibtradition stammende ij-Schreibung für Lateinisch "ii" wird in der norm zu ii normalisiert. |
||
| dipl | clean | norm | |
Lapatijs |
Lapatijs |
Lapatiis |
|
| 3.4 | Ausgestorbenes lexikalisches Material wird mit modernen Orthografieregeln übernommen, aber nicht lexikografisch übersetzt. | ||
| dipl | clean | norm | |
Vergeſz |
Vergeſz |
Vergess |
|
| 3.5 | Es erfolgt keine morphosyntaktische Anpassung (z.B. innerhalb der Nominalphrase) | ||
| dipl | clean | norm | |
(Es) Heylt die verſehrte Daͤrmelein |
(Es) Heylt die versehrte Därmelein |
(Es) Heilt die versehrte Därmlein |
|
| 3.6 | Ausgestorbene Wortbildungsmorpheme werden nach Möglichkeit durch entsprechende nhd. Bildungen ersetzt. (siehe Beispieltabelle am Schluss) | ||
| dipl | clean | norm | |
halben(Postposition) |
halben |
halber (allenthalben ist ein Adverb und bleibt allenthalben) |
|
stachelecht |
stachelecht |
stachelig |
|
| 3.7 | Flexionslose Adjektive, die im Neuhochdeutschen eine overte Flexion enthalten, werden in der norm flektiert, ohne dass der Kasus geändert wird. | ||
| dipl | clean | norm | |
das kal Haupt |
das kal Haupt |
das kahle Haupt |
|
bei ſchweinem fleiſch |
bei schweinem fleisch |
bei schweinenem Fleisch |
|
| 3.8 | Intervenieren innerhalb eines Wortes Sonderzeichen, dann werden die Sonderzeichen in der norm-Ebene ignoriert und das unterbrochene Wort zusammengeschrieben. | ||
| dipl | clean | norm | |
 <lb> <lb>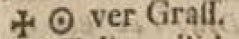 |
|||
Glo- |
Glo ✠ |
Glover |
|
✠ |
|||
⊙ |
⊙ |
||
ver |
ver |
||
Graſſ |
Grass |
Grass |
|
. |
. |
. |
|
| Text hinter (geschweiften) Klammern, wird nach dem umklammerten Textabschnitt eingefügt. | |||
| dipl | |||
 Wermuth Wermuth , gemeiner Wermuth , groſzer ſ. Wer⸗ muthbeifuſz. |
|||
| Graphematisch wird grundsätzlich nach dem Duden normalisiert. | |||
{kind=link}
| Beschreibung | Zeichen | Eingabe über die Tastatur |
|---|---|---|
| Schräger Dopppelbindestrich | ⸗ | 2E17 |
| Langes kleines “s” | ſ | 017F Alt s |
| Tilde | ̃̃ | 0303 |
| Ligatur ae | æ | 00E6 |
| Ligatur AE | Æ | 00C6 |
| Ligatur oe | œ | 0153 |
| Ligatur OE | Π| 0152 |
| Akut | ´ | dead key + |
| Gravis | ` | shift+dead key+ |
| Cedille klein | ç | 00E7 |
| Cedille groß | Ç | 00C7 |
| Superskribiertes “e” | ͤ | 0364 |
| Kreis | å | 030A |
| y mit Punkten | ÿ | 00FF |
| Absatzzeichen | ¶ | 00B6 |
| Abkürzung “der” | ð | AltGr+d |
| Häkchen über Zeichen | v̉ | 0309 |
| Zeichen für lat. “recipe” | ℞ | 211E |
| Zeichen für lat. “libra” | ℔ | 2114 |
| Zeichen für lat. “uncia” | ℥ | 2125 |
| Zeichen für lat. “scrupel” | ℈ | 2108 |
| 3 Kreise | ∴ | 2234 |
| Kreis mit Punkt “einjährig” | ⊙ | 2299 |
| Latin Small Letter Rum Rotunda | ꝝ | A75D |
| Tironisches “et” | ⁊ | 204A |
Tabelle SEQ Tabelle * ARABIC 2: Zeichentabelle
Tabelle: Normalisierungsbeispiele
| clean | norm | |
|---|---|---|
| 1 | -icht/-echt/-acht/-lote | -(l)ich/-(l)ig |
ästicht |
ästig |
|
knöpfflicht |
knöpfflich |
|
haarecht |
haarig |
|
holzecht |
holzig |
|
schattecht |
schattig |
|
langlecht |
länglich |
|
laulecht |
laulig |
|
weißlecht |
weißlich |
|
rohtlecht |
rötlich |
|
stachelecht |
stachelig |
|
gelblote |
gelblich |
|
| 2 | deutlich erkennbare Ortsnamen werden als nhd. Form normalisiert | |
Franckfort |
Frankfurt |
|
Muttetz |
Muttenz |
|
| 3 | -lich-Adverbien werden durch nhd. lich-lose Formen ersetzt | |
kräftiglich |
kräftig |
|
wunderbarlich |
wunderbar |
|
| 4 | für- | vor- |
fürnehmlich |
vornehmlich |
|
| 5 | -für | -vor |
herfür |
hervor |
|
| 6 | on- / ohne entspricht dem Präfix un- | |
on- / ohne |
un- |
|
| 7 | -fnhd. etwan | |
etwan |
nhd. etwa (Adverb)nhd. etwas (Pronomen) |
|
| 8 | -erin | flektierte nhd. Form |
in ein erhabnes Steinerin Grab gelegt |
steinernes |
|
| 9 | -en | -Ø |
endlichen |
endlich |
|
sonsten |
sonst |
|
selbsten |
selbst |
|
| 10 | -Ø | -en |
ob |
oben |
|
beizeit |
beizeiten |
|
| 11 | (Nicht)Normaliserung von Kasus | |
| mit Normalisierung: Man trinke des wassers | mit Normalisierung von Kasus: Man trinke das Wasser |
|
| Man trinke des wassers | ohne Normalisierung von Kasus: Man trinke des Wassers |
|
| 12 | Vom Nhd. abweichende starke oder schwache Verbalflexion bzw. Rückumlaut wird dem nhd. Stand angepasst | |
gennent |
genannt |
|
gebauen |
gebaut |
13 | Auseinanderschreibung |
obgenannt |
oben genannt |
|
hiebevor |
hier bevor |
|
| 14 | ggf. ge-Präfix in Partizipien ergänzen | |
funden |
gefunden |
|
kommen |
gekommen |
|
worden |
geworden |
|
| 15 | Flexionsformen der Pronomina der, die, das an nhd. Formen anpassen | |
der |
derer |
|
dero |
derer |
|
des |
dessen |
|
| 16 | fnhd. wann/wenn | nhd. wann (Interrogativpron) nhd. wenn (Subjunktion) |
wannwenn es einen Nebensatz einleitet → keine V2 Stellung, sondern VLetzt (auch VLetzt mit Nachfeldbesetzung: wenn man Köl- und Haselbaum pflanzt zu Weinreben) |
wenn |
|
wannwenn es einen Hauptsatz einleitet → V2 und übersetzbar it nhd. 'denn' |
wann |
|
wennwenn es einen Hauptsatz einleitet → V2 und übersetzbar it nhd. 'denn' |
wann |
|
wennwenn es einen Nebensatz einleitet → keine V2 Stellung, sondern VLetzt (auch VLetzt mit Nachfeldbesetzung: wenn man Köl- und Haselbaum pflanzt zu Weinreben) |
wenn |
|
| 17 | -fnhd. söllen/wöllen sind dialektale Formen | |
söllen |
sollen |
|
wöllen |
wollen |
|
| 18 | Eigennamen/Fremdwörter in Komposita werden getrennt geschrieben | |
St. Anthonius Feuer |
Sankt Anthonius Feuer |
|
Cassia fistel |
Cassia Fistel |
|
| 19 | Abkürzung frequenter Wörter und Endungen | |
 unn (sic!) |
und |
|
 umm (sic!) |
um |
|
 darumm (sic!) |
darum |
|
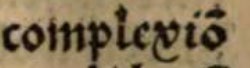 complexiom (sic!) |
Komplexion |
|
| 20 | Einzelentscheidungen | |
benommen |
genommen |
|
Beweisung |
Beweisung |
|
brauch (= Gebrauch) |
Brauch |
|
dannenher |
daher |
|
dennocht |
dennoch |
|
der selbe |
der selbe |
|
derselbe |
derselbe |
|
derowegen |
deswegen |
|
entbeut |
entbietet |
|
Epff |
Epff |
|
fahen |
fangen |
|
gel |
gel |
|
gepreist |
gepriesen |
|
gleichsfallsgleichesfalls |
gleichfalls |
|
guldin |
golden |
|
halb |
halber |
|
harm |
Harn |
|
harmen |
harnen |
|
hauffecht |
häufig |
|
leichtlich |
leicht |
|
liebnusz |
Liebnis |
|
Mannen |
Männern |
|
mehrer |
teils |
|
morgen (= morgens) |
morgens |
|
namlichen |
nämlich |
|
Nutz |
Nutzen |
|
pestnachen |
Pastinaken |
|
samlen |
sammeln |
|
schlahen |
schlagen |
|
sonders |
sonders |
|
(wegen der) Viele |
Viele |
|
vierecket |
viereckig |
|
vor |
vorher |
|
wehtum/wehtumb |
Wehtun |
|
wofer |
wofern |
|
wurz |
wurzel |
|
yedickest |
gedihest (Lexer: 'oft') |
|
yetliches |
jegliches |
|
zeuchen |
ziehen |
|
wa (als dialektale Form) |
wo |
|
Vättern |
Väter |
|
nießte |
neuste |
|
In Verbindung mit Excel benutzte Tools
Excel-Makro
SearchAndMerge.bas: https://hu.berlin/search-and-merge
Das Makro SearchAndMerge.bas sucht in einem markierten Bereich nach leeren Zellen (kleiner gleich 300 leere Zellen nacheinander) und vereinigt diese mit der letzten Vorgängerzelle, die einen Wert enthält.
Python-Skript
clean-skript_V3.py: https://hu.berlin/clean-script-v3
Die neuen Texte ab Version 5 stellten neue Anforderungen an die <clean>-Ebene, neue Zeichenersetzungen wurden nötig sowie ein komplett neuer Umgang mit Nasalstrichen. Die vorigen Texte ließen Zeichenersetzungen der Nasalstriche zu den jeweiligen Nasalen durch Kontextbetrachtung zu, während die neuen Texte viele von diesen alten Regularitäten nicht mehr erfüllen. Deshalb wird ab der zweiten Version des clean-Skriptes anders mit solchen Nasalstrichen verfahren. Statt den Kontext zu betrachten und eine eindeutige Entscheidung zugunsten eines Nasals zu treffen, werden nun alle in Frage kommenden Zeichenersetzungen
berücksichtigt und die möglichen Token werden durch | getrennt dargestellt.
Bei der weiteren Bearbeitung in Excel kann es nach Anwendung des Clean-Skripts zu ungewollten automatischen Formatierungen kommen, ÜBERPRÜFEN!!!
1/2 wurde durch Excel zu 01.Februar. Das normalisierte falsch wurde durch Excel zum logischen Operator FALSCH.